How to Use Whisper

In the ever-evolving world of artificial intelligence, OpenAI has consistently delivered groundbreaking tools that push the boundaries of what is possible. One of their latest creations, Whisper, is an automatic speech recognition system that has garnered significant attention for its impressive accuracy, cost-effectiveness, and ease of use. Whether you’re a student looking to transcribe class notes, a podcaster repurposing audio content, or a video editor adding subtitles, Whisper can be a valuable asset in your workflow. In this comprehensive guide, we will walk you through the process of using Whisper, step by step.
What is OpenAI’s Whisper?
Whisper is an automatic speech recognition system developed by OpenAI, the same team behind ChatGPT and Dalle. As an open-source project, Whisper is freely available for anyone to use, distribute, and modify. Unlike other speech-to-text systems, Whisper does not have a traditional download site. Instead, all the necessary files can be found in OpenAI’s GitHub repository. While this may seem daunting at first, fear not – we will guide you through the installation process, making it accessible even for those less familiar with technical implementations.
Who Can Benefit from Whisper?
Whisper is a versatile tool that caters to a wide range of individuals and professionals who require speech-to-text conversion. Here are just a few examples of how Whisper can be utilized:
Students: Transcribe class notes for easy reference and study.
Meeting Heads: Derive the context of previously recorded Zoom meetings to facilitate follow-up discussions and ensure no details are missed.
Podcasters: Repurpose audio content into various formats, including blog posts, articles, and social media snippets.
Video Editors: Add subtitles to videos to improve accessibility and reach a wider audience.
Researchers: Analyze and extract insights from recorded interviews, lectures, or presentations.
Language Learners: Practice listening comprehension and improve pronunciation by transcribing and analyzing spoken language.
The applications of Whisper are vast, limited only by your imagination and specific needs.

Installing Whisper
Before diving into the exciting world of Whisper, you’ll need to install it on your computer. Unlike traditional software downloads, the installation process for Whisper requires some prerequisite tools and a basic understanding of the command line. Don’t worry if you’re not familiar with these concepts – we’ll guide you through each step.
Prerequisites
To ensure a smooth installation process, make sure you have the following prerequisites on your computer:
Python: Whisper relies on Python, a popular programming language. Head to the Python website and download the version suitable for your operating system. During installation, remember to check the option to add Python to your system’s PATH.

Git: Whisper’s files are hosted on GitHub, so you’ll need to install Git to access and download them. Visit the Git website and choose the installer that matches your device.
Rust: Rust is a programming language used to build certain components of Whisper. Install Rust by either visiting the official Rust website or running the command pip install setuptools-rust in your command interface.
NVIDIA CUDA (optional): If you have an NVIDIA GPU and want to maximize the processing power of Whisper, consider installing NVIDIA CUDA. Visit the NVIDIA website to download the latest CUDA version compatible with PyTorch.

Pip: Pip is a package installer and management tool for Python applications. While newer versions of Python come with Pip pre-installed, older versions may require manual installation. Visit the Pip website for detailed instructions on installing Pip on your system.
PyTorch: PyTorch is a deep-learning library used for running applications on GPUs and CPUs. Whisper relies on PyTorch for its underlying functionality. To install PyTorch, visit the PyTorch website and follow the instructions for your specific use case.
FFmpeg: FFmpeg is a powerful tool for audio and video processing. Whisper requires FFmpeg to handle audio file conversions. Download FFmpeg from the official website and follow the installation instructions for your operating system.
Installing Whisper
Once you have all the prerequisites installed, you’re ready to install Whisper itself. Open your command console and run the following command:
pip install git+https://github.com/openai/whisper.git
Depending on your system configuration, the installation process may take a few minutes. If you encounter any errors related to Git, make sure you have Git properly installed and added to your system’s PATH. Once the installation is complete, you can verify that Whisper is successfully installed by running the command:
whisper -h
This command will display the available options and commands for using Whisper.
Using Whisper
Now that you have Whisper installed, it’s time to put it to use. In this section, we’ll guide you through the process of transcribing speech using Whisper. We’ll cover how to upload an audio file, specify the language, and retrieve the transcribed text.
Uploading an Audio File
To transcribe an audio file, you’ll need to upload it to Whisper. Whisper supports various audio formats, including .mp3, .wav, and .m4a. Follow these steps to upload your audio file:
Create a new folder on your computer and save your audio file in it. Let’s name the folder “Transcribe” for this example.
Open a new command console and navigate to the “Transcribe” folder using the cd command. For example:
cd C:\path\to\Transcribe
Run the following command to transcribe your audio file:
whisper "<file_name>"
Replace <file_name> with the actual name of your audio file, including the file extension. For example, if your audio file is named “interview.wav,” the command would be:
whisper "interview.wav"
Whisper will start transcribing the audio file, and the resulting text files will be saved in the same folder where the audio file is located. The transcribed text files will be available in various formats, such as .json, .srt, .tsv, .txt, and .vtt.
Specifying the Language
By default, Whisper automatically detects the language of the audio file and transcribes it accordingly. However, if you want to specify the language manually, you can do so by adding the --language parameter to the command. For example:
whisper "interview.wav" --language Italian
This command tells Whisper to transcribe the audio file as Italian. Whisper supports a wide range of languages, allowing you to transcribe speech from different linguistic backgrounds.
Choosing the Model
Whisper offers multiple recognition models, each with varying levels of accuracy and processing time. By default, Whisper uses a small model, which is fast but may sacrifice some accuracy. However, you can choose a different model to suit your needs. To specify the model, use the --model parameter followed by the desired model name. For example:
whisper "interview.wav" --model large-v2
In this command, Whisper will use the large-v2 model, which provides higher accuracy at the cost of longer processing time. Experiment with different models to find the right balance between speed and accuracy for your specific use case.
Additional Parameters and Customization
Whisper offers additional parameters and options to further customize your transcription experience. To explore these options, use the whisper -h command, which displays the available commands and their descriptions. For example:
whisper -h
This command will provide a comprehensive list of commands, including options for specifying output formats, adjusting silence thresholds, and more. Familiarize yourself with these commands to make the most out of Whisper’s capabilities.
Whisper’s Accuracy and Language Support
Whisper boasts impressive accuracy in transcribing speech, thanks to its extensive training on over 680,000 hours of multilingual data. However, it’s important to note that no transcription tool is perfect, and Whisper is no exception. While it excels in accuracy, there are still some areas where improvements can be made:

Punctuation: Whisper may occasionally omit or misinterpret punctuation marks in the transcribed text.
Word Accuracy: In some cases, Whisper may transcribe words incorrectly or fail to transcribe certain words altogether.
Speaker Differentiation: Whisper does not provide a distinction between different speakers in the transcribed text.
Despite these limitations, Whisper outperforms many other speech recognition models in terms of accuracy. A research paper comparing Whisper’s Word Error Rate (WER) to other models revealed that Whisper consistently outperforms the best open-source model in all tested datasets.
Whisper supports a wide range of languages, with a total of 99 languages recognized and transcribed. While certain languages, such as English, Spanish, Italian, and Portuguese, achieve a word error rate of less than 5%, others may have higher error rates. Whisper continues to improve its language support, striving to minimize errors across all supported languages.
Whisper vs. Notta: A Free Alternative
While Whisper offers exceptional accuracy and flexibility, it may not be the perfect fit for everyone. If you’re looking for an alternative to Whisper that is compatible with various devices and offers additional features, consider Notta AI Speech Recognition Software.
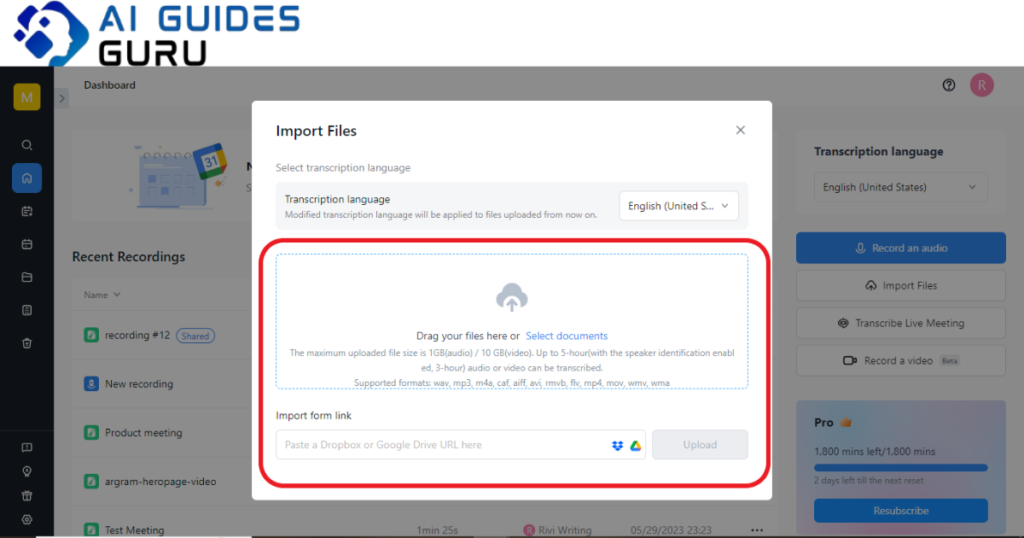
Notta is a powerful transcription and translation tool that boasts an accuracy rate of 99.98%. It supports a staggering 104 languages for transcription and 42 languages for translation, making it one of the most comprehensive AI language tools available. With Notta, you can enjoy real-time meeting transcriptions, AI-generated summaries, and fast turnaround times for transcription tasks.
To use Notta, simply sign up for a free account and choose your preferred method of recording – whether through the Notta web app, Chrome extension, or mobile app. Notta automatically saves all your recordings, allowing you to access and export them at any time. With its user-friendly interface and extensive language support, Notta is an excellent alternative for those seeking a versatile and accurate transcription tool.
Conclusion
OpenAI’s Whisper offers an impressive speech recognition system that can greatly enhance your productivity and streamline your workflow. By following the installation steps outlined in this guide, you can easily harness the power of Whisper to transcribe audio files, whether you’re a student, professional, or language enthusiast. While Whisper is known for its accuracy, it’s essential to keep in mind its limitations and explore alternative tools like Notta for additional features and versatility. Embrace the power of AI transcription and unlock a new level of efficiency in your daily tasks.
Can I use Whisper on my smartphone?
While Whisper should work on most devices, including smartphones, the installation process may vary depending on your operating system. It’s recommended to follow the installation steps on a desktop or laptop computer for optimal results.
Does Whisper support real-time transcription?
No, Whisper currently focuses on asynchronous transcription, meaning you need to provide an audio file for transcription. For real-time transcription, consider using alternative tools like Notta, which offers real-time meeting transcription.
Is Whisper completely free to use?
Yes, Whisper is an open-source project and is available for free. However, keep in mind that installing and using Whisper may require computational resources, such as a compatible GPU, which may have associated costs.